ML-KEM — The Module-Lattice Key-Encapsulation Standard (FIPS 203)
- From the Quantum Threat to a KEM Standard
- What a Key-Encapsulation Mechanism Is
- The Hard Problem: Module-LWE
- The Algebraic Setting
- The K-PKE Component (IND-CPA Encryption)
- From CPA to CCA: Fujisaki-Okamoto With Implicit Rejection
- ML-KEM KeyGen, Encaps, and Decaps
- Parameter Sets and Sizes
- ML-KEM in Context
- Frequently Asked Questions
- Conclusion
- References
ML-KEM is the key-encapsulation mechanism standardized by NIST in FIPS 203, published on 13 August 2024. It is the standardized form of CRYSTALS-Kyber and is the companion to the two signature standards (ML-DSA in FIPS 204 and SLH-DSA in FIPS 205). Where those produce signatures, ML-KEM does something different: it lets two parties agree on a shared secret key over a public channel, the role classically played by Diffie-Hellman key exchange or RSA key transport, both of which a quantum computer breaks. This article explains what a KEM is, the module-lattice problem ML-KEM rests on, the internal K-PKE encryption scheme, the Fujisaki-Okamoto transform with implicit rejection that upgrades it to chosen-ciphertext security, and the three parameter sets.
This article has been made with the help of Claude Code and several custom skills
[TOC]
From the Quantum Threat to a KEM Standard
Most secure channels today (TLS, SSH, IPsec) begin with an ephemeral Diffie-Hellman exchange over an elliptic curve, which establishes a fresh shared secret that then keys symmetric encryption. The security of that step rests on the elliptic-curve discrete logarithm problem, which Shor’s algorithm solves in polynomial time on a large quantum computer. Unlike a signature, a key exchange is exposed to “harvest now, decrypt later”: an adversary can record encrypted traffic today and recover the session keys once it has a quantum computer, retroactively decrypting everything.
The 2016 NIST Post-Quantum Cryptography process (82 submissions) selected a small first set of algorithms. ML-KEM is the key-establishment primitive from that selection, derived from CRYSTALS-Kyber and standardized as FIPS 203. NIST recommends ML-KEM-768 as the default, citing a large security margin at reasonable cost. In deployment ML-KEM is usually run in a hybrid with X25519 (the combined secret keyed from both), so that the channel stays secure if either component is later broken.
What a Key-Encapsulation Mechanism Is
A KEM is not encryption of a chosen message and not an interactive key exchange. It is three algorithms:
- KeyGen produces an encapsulation key (public) and a decapsulation key (private).
- Encaps takes the public encapsulation key and outputs a fresh shared secret $K$ together with a ciphertext $c$ that carries it.
- Decaps takes the private decapsulation key and the ciphertext and recovers the same shared secret $K$.
The flow is one-directional and needs only a single message. Alice generates a key pair and publishes the encapsulation key. Bob runs Encaps against it, keeps $K$, and sends $c$. Alice runs Decaps on $c$ and obtains the same $K$. Both now hold a 256-bit shared secret usable directly for symmetric cryptography.
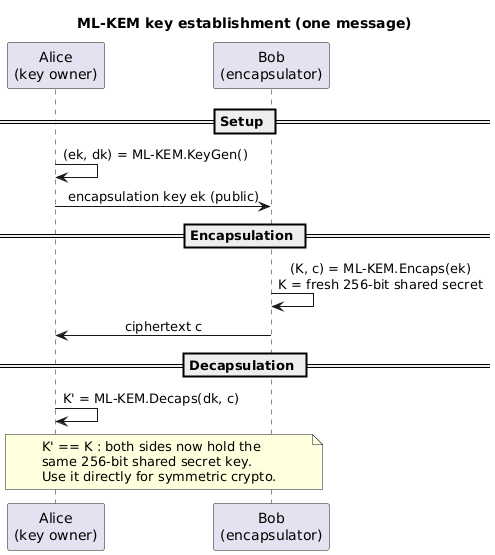
The shared secret is generated inside Encaps, not chosen by Bob. The two halves of that definition (not chosen-message encryption, not interactive key exchange) are worth making explicit, because each one is a deliberate design choice that makes the primitive easier to secure.
Why not encryption of a chosen message. In public-key encryption the sender picks the plaintext and encrypts it under the recipient’s key. A KEM removes that choice: the secret $K$ is produced inside Encaps as a fresh random value, and neither party selects it. This matters because attacker-influenced plaintexts are the raw material of most chosen-ciphertext attacks against lattice encryption. By transporting a value that is random by construction, and (as shown later) deriving the encryption randomness deterministically from that value, ML-KEM removes the degrees of freedom an active attacker would otherwise probe. A KEM is therefore best read as encryption of a random key the algorithm chose, not of data the sender chose, which is both sufficient for session setup and simpler to prove secure.
Why not an interactive key exchange. In Diffie-Hellman both parties contribute a value and the secret is derived jointly from a two-message round trip. A KEM is one-directional: only the key owner holds a long-term key pair, the secret originates entirely on the encapsulator’s side, and a single ciphertext travels back. That asymmetry is what lets ML-KEM slot into protocols organized around a published public key (a TLS certificate, for example) without adding an interactive round, and it is why a KEM composes cleanly with a separate signature for authentication. Put together, a KEM does the job of Diffie-Hellman (agree on a session key) using the shape of public-key encryption (publish a key, return a ciphertext), while carrying a random secret rather than a chosen one. That precise shape is what the Fujisaki-Okamoto transform in the later sections is built to protect.
The Hard Problem: Module-LWE
ML-KEM’s security rests on the Module Learning With Errors (MLWE) problem. In plain LWE, an adversary is given a system of noisy linear equations $\mathbf{A}\mathbf{s} + \mathbf{e} = \mathbf{b}$ over $\mathbb{Z}_q$ and must recover the secret $\mathbf{s}$; the small error $\mathbf{e}$ is what makes standard linear algebra (Gaussian elimination) fail. MLWE replaces the integer vector space $\mathbb{Z}_q^n$ with a module $R_q^k$ over a polynomial ring, which gives structured matrices, smaller keys, and fast arithmetic through the NTT, at the cost of an additional structural assumption. The name module-lattice reflects this.
The encryption idea follows directly: the public key is a noisy linear system $(\mathbf{A}, \mathbf{t} = \mathbf{A}\mathbf{s} + \mathbf{e})$ in the secret $\mathbf{s}$. Anyone can form a new noisy equation in the same secret without knowing $\mathbf{s}$ and hide one bit of information per coefficient in its constant term. Only the holder of $\mathbf{s}$ can strip the noise and read it back. That is the IND-CPA encryption scheme underneath ML-KEM, called K-PKE.
The Algebraic Setting
All arithmetic lives in the ring
[\begin{aligned} R_q = \mathbb{Z}_q[X]/(X^{256}+1), \qquad q = 3329 = 2^8 \cdot 13 + 1, \qquad n = 256. \end{aligned}]
The prime $q$ is chosen so that $X^{256}+1$ splits into 128 quadratic factors modulo $q$, which makes the Number Theoretic Transform (NTT) available. The NTT is a ring isomorphism $R_q \cong T_q$ under which polynomial multiplication becomes cheap coordinate-wise products, so $\mathsf{NTT}(fg) = \mathsf{NTT}(f) \times_{T_q} \mathsf{NTT}(g)$. The twiddle factor is $\zeta = 17$, a primitive 256th root of unity modulo $q$. Because $T_q$ is a product of 128 degree-2 factors (not 256 degree-1 factors, unlike ML-DSA’s $q$), multiplication in $T_q$ uses a small BaseCaseMultiply per coordinate. As in the other standards, no floating-point arithmetic may be used.
The matrix $\mathbf{A}$ is $k \times k$ over $R_q$ and is regenerated from a 32-byte seed $\rho$ rather than stored. The secrets $\mathbf{s}$ and noise $\mathbf{e}, \mathbf{e}1, e_2$ are sampled from a centered binomial distribution $\mathcal{D}\eta(R_q)$ with small coefficients.
The K-PKE Component (IND-CPA Encryption)
K-PKE is an internal public-key encryption scheme. It is not approved standalone; it exists only as a subroutine of ML-KEM. It has three algorithms.
KeyGen expands a seed $d$ into $(\rho, \sigma)$, builds $\hat{\mathbf{A}}$ from $\rho$, samples $\mathbf{s}$ and $\mathbf{e}$ from the binomial distribution, and computes the noisy system in the NTT domain:
[\begin{aligned} \hat{\mathbf{t}} = \hat{\mathbf{A}} \circ \hat{\mathbf{s}} + \hat{\mathbf{e}}. \end{aligned}]
The encryption key is $\mathsf{ek_{PKE}} = \mathsf{ByteEncode}(\hat{\mathbf{t}}) \,|\, \rho$, and the decryption key is $\mathsf{dk_{PKE}} = \mathsf{ByteEncode}(\hat{\mathbf{s}})$.
Encrypt takes the encryption key, a 32-byte message $m$, and randomness $r$. It regenerates $\hat{\mathbf{A}}$, samples a fresh vector $\mathbf{y}$ and noise $\mathbf{e}_1, e_2$, and forms a second noisy equation, adding the message encoded into the constant term:
[\begin{aligned}
\mathbf{u} &= \mathsf{NTT}^{-1}(\hat{\mathbf{A}}^\top \circ \hat{\mathbf{y}}) + \mathbf{e}_1,
v &= \mathsf{NTT}^{-1}(\hat{\mathbf{t}}^\top \circ \hat{\mathbf{y}}) + e_2 + \mathsf{Decompress}_1(m).
\end{aligned}]
Both parts are compressed (dropping low-order bits via $d_u, d_v$) and serialized: $c = (c_1 \,|\, c_2)$.
Decrypt recovers $\mathbf{u}’, v’$ from the ciphertext and uses the secret to compute $w = v’ - \mathsf{NTT}^{-1}(\hat{\mathbf{s}}^\top \circ \mathsf{NTT}(\mathbf{u}’))$, then decodes $m$ from $w$. The noise terms are small enough that compression and the leftover error round away, so $m$ is recovered correctly with overwhelming probability.
K-PKE alone is only IND-CPA secure: safe against a passive eavesdropper, but not against an attacker who can submit crafted ciphertexts and observe decryption behavior. A KEM must withstand the latter.
From CPA to CCA: Fujisaki-Okamoto With Implicit Rejection
ML-KEM upgrades K-PKE to IND-CCA2 security (resistance to chosen-ciphertext attacks) with a variant of the Fujisaki-Okamoto (FO) transform. The construction uses three hash functions from FIPS 202: $G = \text{SHA3-512}$ (producing two 32-byte outputs), $H = \text{SHA3-256}$, and $J = \text{SHAKE256}$.
The central trick is derandomized re-encryption. In Encaps, the message $m$ is itself random, and both the shared secret $K$ and the encryption randomness $r$ are derived deterministically from it:
[\begin{aligned} (K, r) = G(m \,|\, H(\mathsf{ek})), \qquad c = \mathsf{K\text{-}PKE.Encrypt}(\mathsf{ek}, m, r). \end{aligned}]
Because $r$ comes from $m$, there is exactly one valid ciphertext for each $m$. Decaps exploits this: it decrypts $c$ to recover a candidate $m’$, re-derives $(K’, r’)$ from $m’$, and re-encrypts with $r’$ to obtain $c’$. If $c’ = c$, the ciphertext was honestly formed and $K’$ is returned. If not, the ciphertext is malformed or tampered, and Decaps performs an implicit rejection: instead of returning an error, it returns a pseudorandom but deterministic value
[\begin{aligned} \bar{K} = J(z \,|\, c), \end{aligned}]
where $z$ is a secret 32-byte value stored in the decapsulation key.
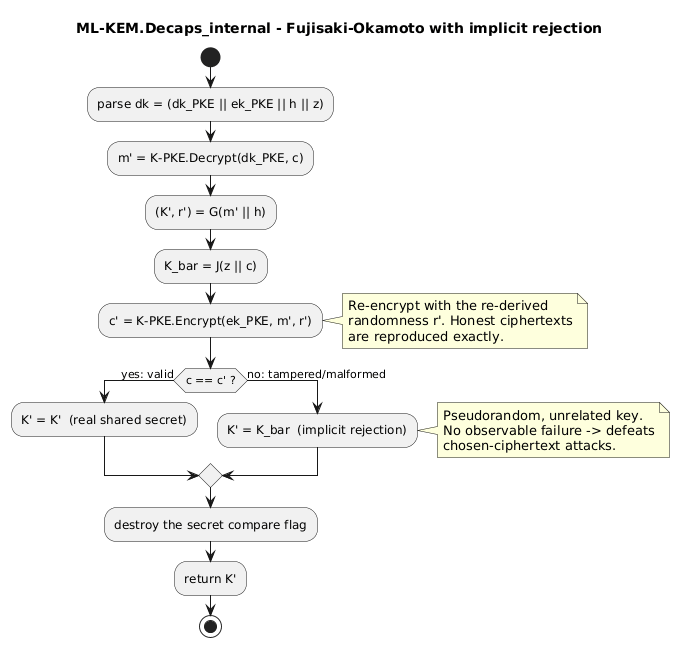
Implicit rejection is what defeats chosen-ciphertext attacks. A classic CCA attack feeds modified ciphertexts to the decryptor and learns the secret from whether each one decrypts successfully. With implicit rejection there is no observable failure: a bad ciphertext yields a key that is random-looking and unrelated to any real session, so the attacker learns nothing from submitting it. The comparison flag ($c$ versus $c’$) is itself secret data and must be destroyed before Decaps returns.
ML-KEM KeyGen, Encaps, and Decaps
The public ML-KEM algorithms wrap K-PKE with the FO machinery. They split into “internal” deterministic functions (used for testing) and external functions that draw their own randomness.
KeyGen generates two 32-byte seeds $d, z$ and bundles the K-PKE keys with the implicit-rejection value:
[\begin{aligned} \mathsf{ek} = \mathsf{ek_{PKE}}, \qquad \mathsf{dk} = (\mathsf{dk_{PKE}} \,|\, \mathsf{ek} \,|\, H(\mathsf{ek}) \,|\, z). \end{aligned}]
The decapsulation key carries everything Decaps needs: the K-PKE decryption key, the encapsulation key (to re-encrypt), a hash of it, and $z$.
Encaps draws a random 32-byte $m$, computes $(K, r) = G(m \,|\, H(\mathsf{ek}))$, encrypts to get $c$, and returns $(K, c)$.
Decaps parses $\mathsf{dk}$, decrypts $c$ to $m’$, recomputes $(K’, r’) = G(m’ \,|\, h)$ and $\bar{K} = J(z \,|\, c)$, re-encrypts $m’$ under $r’$ to get $c’$, and returns $K’$ if $c = c’$ or the implicit-rejection $\bar{K}$ otherwise.
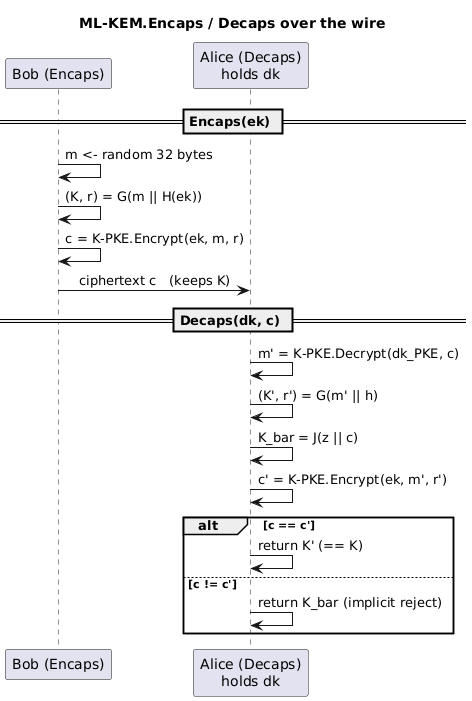
A subtle but mandatory detail is input checking. Before Encaps runs, the encapsulation key must pass a type check (correct byte length $384k + 32$) and a modulus check (a ByteDecode/ByteEncode round-trip must be the identity, proving every coefficient is in range $[0, q-1]$). Before Decaps runs, the decapsulation key must pass a type check and a hash check (the stored $H(\mathsf{ek})$ must match). Ciphertext length must always be verified. Skipping these checks can break the security guarantees.
Parameter Sets and Sizes
FIPS 203 specifies three parameter sets. Only $k$ and the noise/compression parameters change; $n = 256$ and $q = 3329$ are fixed.
| Parameter | ML-KEM-512 | ML-KEM-768 | ML-KEM-1024 |
|---|---|---|---|
| $k$ (module rank) | 2 | 3 | 4 |
| $\eta_1$ | 3 | 2 | 2 |
| $\eta_2$ | 2 | 2 | 2 |
| $d_u$ | 10 | 10 | 11 |
| $d_v$ | 4 | 4 | 5 |
| Required RBG strength (bits) | 128 | 192 | 256 |
| Security category | 1 | 3 | 5 |
The encoded sizes follow from $k$ and the compression parameters. The shared secret is always 256 bits.
| Size (bytes) | ML-KEM-512 | ML-KEM-768 | ML-KEM-1024 |
|---|---|---|---|
| Encapsulation key | 800 | 1184 | 1568 |
| Decapsulation key | 1632 | 2400 | 3168 |
| Ciphertext | 768 | 1088 | 1568 |
| Shared secret | 32 | 32 | 32 |
The categories map to the NIST levels (1 ≈ AES-128 key search, 3 ≈ AES-192, 5 ≈ AES-256). Keys and ciphertexts are roughly one kilobyte, far larger than the 32 bytes of an X25519 public value, which is the bandwidth cost of post-quantum key establishment. NIST recommends ML-KEM-768 as the default.
ML-KEM in Context
ML-KEM sits beside the two signature standards but solves a different problem. A quick orientation:
| ML-KEM (FIPS 203) | ML-DSA (FIPS 204) | SLH-DSA (FIPS 205) | |
|---|---|---|---|
| Purpose | Key establishment | Signatures | Signatures |
| Family | Lattice (MLWE) | Lattice (MLWE) | Hash-based |
| Security goal | IND-CCA2 | SUF-CMA | EUF-CMA |
| Public artifact | ek 800–1568 B | pk 1.3–2.6 KB | pk 32–64 B |
| Transmitted | ciphertext 768–1568 B | sig 2.4–4.6 KB | sig 8–50 KB |
ML-KEM replaces Diffie-Hellman / RSA key transport; it does not authenticate anyone. Authentication still needs a signature (ML-DSA or SLH-DSA) or a pre-shared certificate, exactly as ECDH on its own does not authenticate. A typical post-quantum TLS handshake combines a hybrid ML-KEM key exchange with an ML-DSA certificate chain.
Frequently Asked Questions
Q: How does a KEM differ from public-key encryption and from a key exchange?
A KEM transports a randomly generated shared secret, not a chosen message. Encaps produces the secret $K$ internally and a ciphertext $c$ that encapsulates it; Decaps recovers $K$ from $c$. Unlike public-key encryption, the sender cannot pick the payload (which makes the construction simpler to secure and exactly fits session-key setup). Unlike an interactive Diffie-Hellman exchange, it is one-directional: a single ciphertext flows from the encapsulator to the key owner. The result is a 256-bit secret both sides share, usable directly for symmetric cryptography.
Q: Why is K-PKE not approved for use on its own?
K-PKE is only IND-CPA secure, meaning it withstands a passive eavesdropper but not an active attacker who submits crafted ciphertexts and observes how they decrypt. Such chosen-ciphertext attacks can extract the secret key from a raw lattice PKE. ML-KEM wraps K-PKE in the Fujisaki-Okamoto transform to reach IND-CCA2 security, so FIPS 203 exposes only the wrapped KEM and forbids using K-PKE standalone.
Q: What is implicit rejection and why does it matter?
When Decaps re-encrypts the recovered message and the resulting ciphertext does not match the received one, the ciphertext is invalid. Rather than returning an error (which would tell an attacker that decryption failed), ML-KEM returns a pseudorandom value $\bar{K} = J(z \,|\, c)$ derived from a secret $z$ in the decapsulation key and the ciphertext. The caller cannot distinguish this from a real shared secret, so a chosen-ciphertext attacker learns nothing from probing with malformed ciphertexts. This silent failure is what gives ML-KEM its CCA security.
Q: Why does the encryption randomness $r$ come from the message $m$, and what does that enable?
In Encaps, $(K, r) = G(m \,|\, H(\mathsf{ek}))$, so the randomness is a deterministic function of $m$. This makes encryption derandomized: for a given $m$ there is exactly one valid ciphertext. Decaps uses that property to verify integrity by re-encrypting the decrypted $m’$ with the re-derived $r’$ and checking that it reproduces the received ciphertext. Without binding $r$ to $m$, the re-encryption check (and therefore the FO transform’s CCA security) would be impossible.
Q: Combining the algebra and the transform, trace how the same shared secret ends up on both sides.
Bob runs Encaps: he picks random $m$, computes $(K, r) = G(m \,|\, H(\mathsf{ek}))$, and sends $c = \mathsf{K\text{-}PKE.Encrypt}(\mathsf{ek}, m, r)$, keeping $K$. Alice runs Decaps: using her secret $\hat{\mathbf{s}}$ she decrypts $c$ to recover $m’ = m$ (the lattice noise rounds away, so decryption is correct with overwhelming probability), then recomputes $(K’, r’) = G(m’ \,|\, h)$. Since $m’ = m$ and $h = H(\mathsf{ek})$, she gets $K’ = K$. She re-encrypts with $r’$ and confirms $c’ = c$, so she returns $K’ = K$ rather than the implicit-rejection value. Both sides now hold the identical 256-bit secret, and its secrecy reduces to MLWE because recovering $m$ (or $\mathbf{s}$) from $c$ and $\mathsf{ek}$ is an MLWE instance.
Q: ML-KEM establishes a key but is often deployed in a hybrid with X25519 and alongside a signature. Why both?
Two separate reasons. The hybrid with X25519 hedges the assumption: the session key is derived from both the ML-KEM secret and the ECDH secret, so the channel stays secure as long as either lattice or elliptic-curve security holds, which protects against an unforeseen weakness in the new scheme. The signature addresses a different gap: a KEM provides confidentiality but no authentication, so on its own it is vulnerable to a man-in-the-middle who substitutes their own encapsulation key. A signature (ML-DSA or SLH-DSA) over the handshake, anchored in a certificate, authenticates the parties. Confidentiality and authentication are distinct services, and ML-KEM supplies only the first.
Conclusion
ML-KEM is the post-quantum replacement for Diffie-Hellman key establishment. It builds an IND-CPA encryption scheme, K-PKE, on the module-LWE problem, then applies the Fujisaki-Okamoto transform with implicit rejection to reach IND-CCA2 security: Encaps derives both the shared secret and the encryption randomness from a random message, and Decaps re-encrypts to detect tampering, returning a pseudorandom key instead of an error when the check fails. The three parameter sets vary only the module rank and the compression parameters, producing keys and ciphertexts of roughly one kilobyte and a 256-bit shared secret, with ML-KEM-768 as the recommended default. ML-KEM supplies confidentiality only, so real deployments pair it with a signature for authentication and often with X25519 for assumption hedging.
References
- FIPS 203 — Module-Lattice-Based Key-Encapsulation Mechanism Standard
- FIPS 204 — Module-Lattice-Based Digital Signature Standard
- FIPS 205 — Stateless Hash-Based Digital Signature Standard
- CRYSTALS-Kyber — Algorithm Specifications and Supporting Documentation
- FIPS 202 — SHA-3 Standard: Permutation-Based Hash and Extendable-Output Functions
- NIST SP 800-227 — Recommendations for Key-Encapsulation Mechanisms
- NIST Post-Quantum Cryptography Standardization
- Claude Code